로컬 서버에 애플리케이션과 데이터베이스가 있어 스탠드얼론으로 구동도 되면서 관제 서버에 필요한 데이터를 동기화 시켜주는 프로젝트 업무를 맡게 되었는데, 데이터 동기화 부분을 애플리케이션으로 해결하면 사이드 이펙트와 신경써야 할 포인트가 많이 생길 거 같아 이미 만들어진 시스템으로 해결할 방법은 없을까? 생각하면서 찾아 보던 중 kafka connect를 알게 되었고 저와 같은 내용으로 고민하시는 분들을 위해 글을 작성하게 되었습니다.
■시스템 구성도
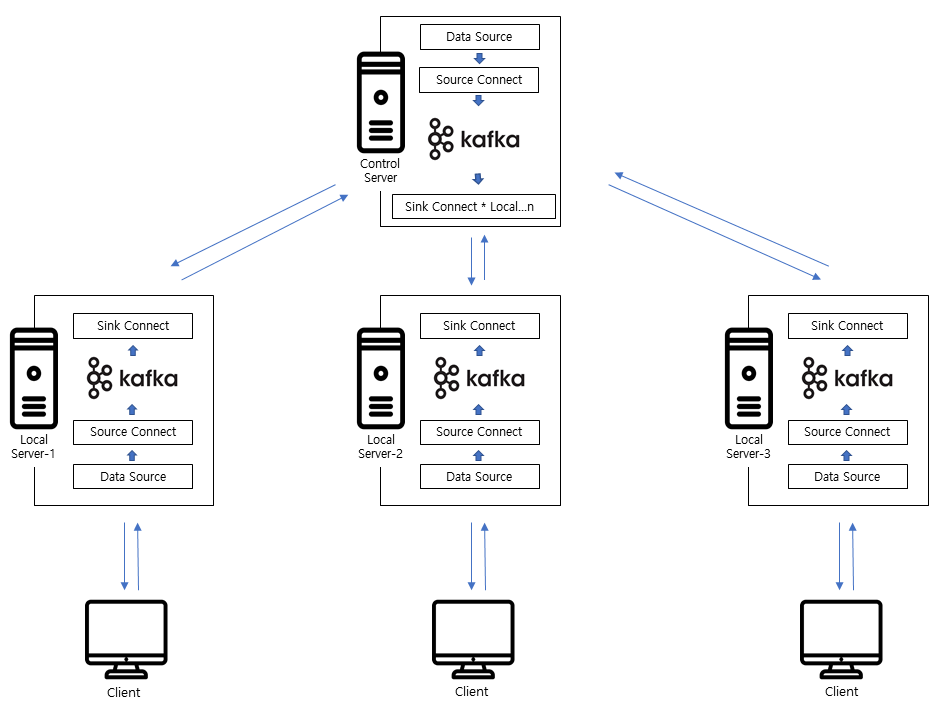
시스템 구성은 보는바와 같이 로컬 서버는 여러 대가 있고 각각에 로컬 서버마다 로컬 db를 가지고 있어 개별로도 서비스가 가능하며 원하는 시점에 관제 서버와 연결하여 관제 서버에서 필요한 데이터를 동기화시켜주는 구조입니다.
아래는 해당 시스템을 구현하기 위해 카프카 커넥트 설치와 더불어 필요한 프로그램과 운영에 필요한 내용들을 정리하였습니다.
■Java 설치
1. java 다운로드
shell> sudo yum install java-1.8.0-openjdk
■MariaDB 설치
1. 기존 버전 확인(저 같은 경우는 10.4버전을 이용하였으며 이는 필수 사항이 아닙니다.)
shell> rpm -qa | grep -i mariadbmariadb로 시작하는 패키지가 있다면 아래 명령어로 삭제합니다
shell> sudo yum remove mariadb*
2. package 로 설치하기 위해 mariadb 저장소 정보를 추가합니다.
shell> sudo tee /etc/yum.repos.d/MariaDB.repo<<EOF
[mariadb]
name = MariaDB
baseurl = http://yum.mariadb.org/10.4/centos7-amd64
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=1
EOF
3. 저장소를 업데이트합니다.
shell> sudo yum makecache fast
4. 설치
shell> sudo yum install MariaDB-client MariaDB-server
5. encoding설정
shell> sudo vi /etc/my.cnf – 아래내용 추가
[mysqld]
init_connect="SET collation_connection = utf8_general_ci"
init_connect="SET NAMES utf8"
character-set-server = utf8
collation-server = utf8_general_ci
[client]
default-character-set = utf8
[mysqldump]
default-character-set = utf8
[mysql]
default-character-set = utf8
6. 부팅 시 자동으로 구동되도록 설정합니다.
shell> sudo systemctl list-unit-files | grep mariadb (mariadb 자동 실행 상태 확인 mariadb.service가 disabled시 아래 활성화 명령어 실행.)
shell> sudo systemctl enable mariadb
7. mariadb 서비스를 시작.
shell> sudo systemctl restart mariadb
8. 특정 DB내부, 외부 접속용 계정 추가 (필요시)
$ sudu mysql (root 권한으로 접속)
MariaDB [(none)]> CREATE USER 'testor'@'%' IDENTIFIED BY '1234';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON test.* TO 'testor'@'%' IDENTIFIED BY '1234';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON test.* TO 'testor'@localhost IDENTIFIED BY '1234';
MariaDB [(none)]> FLUSH PRIVILEGES;- 정상 등록 확인
MariaDB [(none)]> SELECT Host,User,plugin,authentication_string FROM mysql.user;- 계정 권한 조회
MariaDB [(none)]> SHOW GRANTS FOR 'testor'@'%';
db세팅 완료 후 테이블은 아래와 같이 테이블을 생성해 줍니다.
-로컬 서버
CREATE TABLE `kafka_test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`text` varchar(100) DEFAULT NULL,
`code` varchar(100) NOT NULL,
`create_date` datetime NOT NULL,
`modify_date` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `kafka_test2_UN` (`id`,`code`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
-관제 서버
CREATE TABLE `kafka_test` (
`master_id` bigint(20) NOT NULL AUTO_INCREMENT,
`id` bigint(20) DEFAULT NULL,
`text` varchar(100) DEFAULT NULL,
`code` varchar(100) NOT NULL,
`create_date` datetime NOT NULL,
`modify_date` datetime NOT NULL,
PRIMARY KEY (`master_id`),
UNIQUE KEY `kafka_test2_UN` (`id`,`code`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;관제 서버는 데이터베이스는 1:n구조로 설계하였으며 id, code를 unique key로 묶어서 동기화시 해당 칼럼을 기준으로 업데이트시킵니다. 이 구조에서 로컬 서버가 데이터를 생성하는 주체이며 관제 서버는 로컬 서버가 올려준 데이터를 수정만 할 수 있습니다.
■ Kafka설치
1. kafka 다운로드(home디렉토리에 설치)
shell> wget http://apache.mirror.cdnetworks.com/kafka/2.8.1/kafka_2.12-2.8.1.tgz
2. kafka 압축해제
shell> tar xvf kafka_2.12-2.8.1.tgz
3. 심볼릭 링크 생성
shell> ln -s kafka_2.12-2.8.1 kafka
4. kafka topic 보관주기 설정(필요시)
shell> vi ~/kafka/config/server.properties (아래 내용 수정)
log.retention.hours=168 (시간단위로 설정 default는 168시간 일주일)-변경된 사항 확인
shell> grep -i 'log.retention.[hms].*\=' ~/kafka/config/server.properties
5. kafka data저장 위치 변경.
운영도중 error shutdown broker because all log dirs in /tmp/kafka-logs have failed와 같은 에러를 내면서
카프가 서비스가 셧다운 되는 현상을 발견하였고,
https://shinwusub.tistory.com/130
위에 링크를 참고하여 기본으로 설정 되어 있는 /tmp경로를 home디렉토리로 변경 하였다.
글을 작성하신 분은 확실치 않다고 하였으나 이렇게 기본 경로를 변경한 뒤에 더이상 셧다운 관련 에러는 발생하지 않았다.
shell> vi ~/kafka/config/server.properties
log.dirs=/tmp/kafka-logs(default /tmp 경로를 다른 위치로 변경.)
vi ~/kafka/config/zookeeper.properties
dataDir=/tmp/zookeeper(default /tmp 경로를 다른 위치로 변경.)
6. kafka topic 삭제 기능 설정
shell> vi ~/kafka/config/server.properties (아래 내용으로 수정)
delete.topic.enable=true
■ Kafka Connect설치
1. connect 다운로드(home디렉터리에 설치)
shell> wget https://packages.confluent.io/archive/6.2/confluent-community-6.2.2.tar.gz
2. connect 압축해제
shell> tar -xvf confluent-community-6.2.2.tar.gz
3. 심볼릭 링크 생성
shell> ln -s confluent-6.2.2 kafka-connect
■ JDBC connector설치
1. confluent-hub 설치(home디렉터리에 설치)
shell> wget http://client.hub.confluent.io/confluent-hub-client-latest.tar.gz
2. confluent-hub 압축해제
shell> tar xvf confluent-hub-client-latest.tar.gz
3. JDBC connector다운로드
shell> confluent-hub install confluentinc/kafka-connect-jdbc:10.3.3 --component-dir .
4. kafka connect에 JDBC connect 연결
shell> vi ~/kafka-connect/etc/kafka/connect-distributed.properties 아래 내용으로 수정
plugin.path=/{JDBC설치 경로}/confluentinc-kafka-connect-jdbc/lib
5. 연결 확인. 아래 내용 출력되는지 체크(필요시 kafka connect서버 가동 후. 확인)
shell> curl http://localhost:8083/connector-plugins | python -m json.tool
-출력 내용
{
"class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"type": "sink",
"version": "10.3.3"
},
{
"class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"type": "source",
"version": "10.3.3"
},
■ MariaDB connect설치
1. 다운로드 디렉토리 이동
shell> cd ~/kafka-connect/share/java/kafka
2. mariadb connect다운로드
shell> wget https://downloads.mariadb.com/Connectors/java/connector-java-2.7.3/mariadb-java-client-2.7.3.jar
■ Service등록
1. zookeeper서비스 등록
shell> sudo vi /usr/lib/systemd/system/zookeeper.service (아래 내용 추가)
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User={user작성}
Group={user grop작성}
ExecStart=/bin/sh -c '~/kafka/bin/zookeeper-server-start.sh ~/kafka/config/zookeeper.properties'
ExecStop=~/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
2. kafka서비스 등록
shell> sudo vi /usr/lib/systemd/system/kafka.service (아래 내용 추가)
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User={user작성}
Group={user grop작성}
ExecStart=/bin/sh -c '~/kafka/bin/kafka-server-start.sh ~/kafka/config/server.properties'
ExecStop=~/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
3. connect서비스 등록
shell> sudo vi /usr/lib/systemd/system/kafka-connect.service (아래 내용 추가)
[Unit]
Requires=kafka.service
After=kafka.service
[Service]
Type=simple
User={user작성}
Group={user grop작성}
ExecStart=/bin/sh -c '~/kafka-connect/bin/connect-distributed ~/kafka-connect/etc/kafka/connect-distributed.properties'
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
4. 서비스 등록 변경사항 전용
shell> sudo systemctl daemon-reload
5. 부팅 시. 자동 실행 설정
shell> sudo systemctl enable zookeeper
shell> sudo systemctl enable kafka
shell> sudo systemctl enable kafka-connect
6. 직접 실행 서비스 실행(아래와 같이 순서대로 실행.)
shell> sudo systemctl start zookeeper
shell> sudo systemctl start kafka
shell> sudo systemctl start kafka-connect
7. 서비스 상태 확인
shell> sudo systemctl status zookeeper
shell> sudo systemctl status kafka
shell> sudo systemctl status kafka-connect
8. 서비스 상태가 running 인 목록 확인.
shell> systemctl list-units --state=active | grep -e zookeeper -e kafka
여기 까지 실행을 했다면 커넥트를 생성할 준비가 완료되었습니다.
설치된 파일들의 내용은 아래 사진과 같이 설치가 되어 있을 겁니다.

■ Local Server Connect등록
1. source connect등록
shell> curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/local_source/config \
-d '{
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://localhost:3306/test",
"connection.user":"testor",
"connection.password":"1234",
"mode": "timestamp+incrementing",
"incrementing.column.name":"id",
"timestamp.column.name":"modify_date",
"table.whitelist":"kafka_test",
"topic.prefix" : "my_topic_",
"tasks.max" : "1"
}'
2. sink connect등록
shell> curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/local_sink/config \
-d '{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://{Control Server IP}:3306/test",
"connection.user":"testor",
"connection.password":"1234",
"auto.create":"false",
"auto.evolve":"false",
"tasks.max":"1",
"topics.regex": "my_topic_.(.*)",
"table.name.format":"${topic}",
"insert.mode":"upsert",
"pk.fields": "id,code",
"pk.mode": "record_value",
"transforms":"dropPrefix",
"transforms.dropPrefix.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.dropPrefix.regex":"my_topic_(.*)",
"transforms.dropPrefix.replacement":"$1"
}'
■ Control Server Connect등록
1. source connect등록
shell> curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/control_source/config \
-d '{
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://localhost:3306/test",
"connection.user":"testor",
"connection.password":"1234",
"mode": "timestamp",
"timestamp.column.name":"modify_date",
"table.whitelist":"kafka_test",
"topic.prefix" : "my_topic_",
"tasks.max" : "1"
}'
2. sink connect등록
shell> curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/local-1_sink/config \
-d '{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://{Station Server IP}:3306/test",
"connection.user":"testor",
"connection.password":"1234",
"auto.create":"false",
"auto.evolve":"false",
"tasks.max":"1",
"topics.regex": "my_topic_.(.*)",
"table.name.format":"${topic}",
"insert.mode":"update",
"pk.fields": "id,code",
"pk.mode": "record_value",
"transforms":"dropPrefix,ReplaceField",
"transforms.dropPrefix.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.dropPrefix.regex":"my_topic_(.*)",
"transforms.dropPrefix.replacement":"$1",
"transforms.ReplaceField.type":"org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.ReplaceField.blacklist":"master_id"
}'
커넥터를 생성하는 옵션은 공홈에서 참고하면 되며 잘 나와 있지 않은 몇 가지 옵션에 대해 설명하자면,
dropPrefix옵션은 kafka source 커넥터를 생성할 때 topic prefix를 지정해 주는데 해당 옵션을 안 주면 기본적으로 {topic prefix + target table} 명으로 테이블을 찾기 때문에 topic prefix를 제거해 주는 옵션이다.
ReplaceField옵션은 관제서버에서 데이터를 수정했을 때 모든 레코드 데이터가 로컬 서버로 보내지게 되는데
이때 로컬 서버에는 master_id칼럼이 없기 때문에 에러가 발생된다. 그렇기 때문에 해당하는 칼럼에 데이터를 제거해주는 옵션이다.
※로컬 서버 커넥터는 설정은 각각 로컬에서 진행하기에 커넥터 네임을 신경 쓸 필요 없이 그대로 등록해 주면 되고,
관제 서버 커넥터에 sink커넥터는 설정한 동기화를 시킬 로컬 서버만큼 네이밍을 구분해서 n개로 등록해 주면 된다.
모든 커넥터를 등록 후 데이터를 등록하면 아래와 같이 동기화가 된다.
만약에 뜻대로 안 될 경우 에러 로그를 참고하며 해결해 나가면 됩니다.
카프카 로그는 카프카 설치 폴더 logs에 커넥터 로그는 커넥터 설치 폴더 logs에서 확인할 수 있습니다.
- 로컬 서버 1 테이블
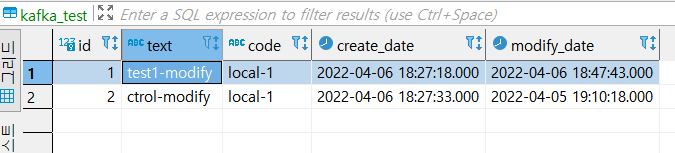
- 로컬 서버 2 테이블

- 관제 서버 테이블

■ Connector 명령어 정리
1. connector목록 조회
shell> curl http://localhost:8083/connectors
2. 특정 connector 상태 조회
shell> curl -X GET "http://localhost:8083/connectors/{connector name}/status"
3. connector 복귀
shell> curl -X PUT "http://localhost:8083/connectors/{connector name}/resume"
4. connector 재시작
shell> curl -X POST "http://localhost:8083/connectors/{connector name}/restart"
5. connector 일시중지
shell> curl -X DELETE -s "http://localhost:8083/connectors/{connector name}"
6. connector 삭제
shell> curl -X DELETE -s "http://localhost:8083/connectors/{connector name}"
7. connector의 task 목록 조회
shell> curl -X GET "http://localhost:8083/connectors/{connector name}/tasks"
8. connector의상태 조회
shell> curl -X GET "http://localhost:8083/connectors/{connector name}/tasks/0/status"
9. connector의재시작(connector 상태가 fail일 때 사용.)
shell> curl -X POST "http://localhost:8083/connectors/{connector name}/tasks/0/restart"
■ Kafka Topic명령어 정리
1. topic생성(connector를 등록하면 자동 생성됨.)
shell> ~/kafka/bin/kafka-topics.sh --create --topic {topic name} --bootstrap-server localhost:9092 --partitions 1
2. topic 목록
shell> ~/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
3. topic 상세
shell> ~/kafka/bin/kafka-topics.sh --describe --topic {topic name} --bootstrap-server localhost:9092
4. 메시지 생성
shell> ~/kafka/bin/kafka-console-producer.sh --topic {topic name} --bootstrap-server localhost:9092
5. 메시지 확인
shell> ~/kafka/bin/kafka-console-consumer.sh --topic {topic name} --from-beginning --bootstrap-server localhost:9092
6. topic 삭제
shell> ~/kafka/bin/kafka-topics.sh --delete --topic {topic name} --bootstrap-server localhost:9092
아래 내용은 번외로 운영에 필요한 shell script를 작성에 대해 기재했습니다.
필요하신 분들은 참고하시면 되겠습니다.
■ CronTab등록
1. kafka관련 서버 log삭제 shell script 작성(home 디렉토리에 작성.)
shell> vi ~/delete_kafka-log.sh (아래 내용 추가)
#!/bin/sh
#생성 된지 90일이 지난 로그를 삭제하는 Script
/usr/bin/find $HOME/kafka/logs/controller.log.* -type f -mtime +90 -exec rm {} +
/usr/bin/find $HOME/kafka/logs/server.log.* -type f -mtime +90 -exec rm {} +
/usr/bin/find $HOME/kafka/logs/state-change.log.* -type f -mtime +90 -exec rm {} +
/usr/bin/find $HOME/kafka/logs/log-cleaner.log.* -type f -mtime +90 -exec rm {} +
/usr/bin/find $HOME/kafka-connect/logs/connect.log.* -type f -mtime +90 -exec rm {} +
2. 네트워크 문제 등. connect연결이 끊겨 task가 failed 되었을 때를 대비한 shell script 작성(home 디렉토리에 작성.)
shell> vi ~/kafka-connect-crontab.sh (아래 내용 추가)
#!/bin/sh
RESULT=$(curl -X GET http://localhost:8083/connectors)
echo "result: ${RESULT}"
arr=$(echo $RESULT | sed -e "s/\[//g;s/\]//g;s/\"//g;s/,/ /g")
echo $arr
if [ ${#arr[@]} -eq 0 ]; then
echo "No value"
else
for connect in ${arr[@]}; do
if [[ "$connect" == *"sink"* ]]; then
echo $connect
res=$(curl -X POST http://localhost:8083/connectors/$connect/tasks/0/restart)
echo -e "res: ${res} \n"
fi
done
fi
3. 실행 권한 부여
shell> chmod 755 ~/delete_kafka-log.sh ~/kafka-connect-crontab.sh
4. crontab등록
shell> crontab -e (아래 내용 추가)
#매일 0시 0분에 실행.
0 0 * * * ~/delete_kafka-log.sh
#매일 0시 5분에 실행.
5 0 * * * ~/kafka-connect-crontab.sh
shell> crontab -l (설정 확인)
여기까지 읽어주셔서 감사합니다.
참고로 제가 설계한 구조에서는 로컬 서버-등록, 수정, 관제 서버-수정만 가능한데 해당 구조에서 삭제까지 구현하신 분이 혹시 생기신다면 댓글로 공유해 주시면 감사하겠습니다.
댓글